초록
As Large Language Models (LLMs) are increasingly deployed in sensitive domains, traditional data privacy measures prove inadequate for protecting information that is implicit, contextual, or inferable - what we define as semantic privacy.
This Systematization of Knowledge (SoK) introduces a lifecycle-centric framework to analyze how semantic privacy risks emerge across input processing, pretraining, fine-tuning, and alignment stages of LLMs.
We categorize key attack vectors and assess how current defenses, such as differential privacy, embedding encryption, edge computing, and unlearning, address these threats.
Our analysis reveals critical gaps in semantic-level protection, especially against contextual inference and latent representation leakage.
We conclude by outlining open challenges, including quantifying semantic leakage, protecting multimodal inputs, balancing de-identification with generation quality, and ensuring transparency in privacy enforcement.
This work aims to inform future research on designing robust, semantically aware privacy-preserving techniques for LLMs.
LLM은 민감하게 성장하는 도미인으로 전통적인 정보보호 프라이버시 정보보호의 암시적, 의미론적, 추론적인 방법으로 증명하는 것은 부적절하다는 것이 증명되었다. 우리는 시맨틱(의미론적) 프라이버시를 정의하는 것.
이 지식 체계화 (SoK)는 의미론적 프라이버시가 입력처리, 사전학습, 미세조정학습, 정렬되는 과정에서 어떻게 리스크가 나타나는지 분석하기 위해 라이프사이클 중심 프레임워크를 도입한다.
주요 공격 벡터(요소)들을 분류하고 평가한다. 예를 들어 차등프라이버시, 암호화, 엣지컴퓨팅, 언러닝 등의 현재 방어가 이러한 위협에 어떻게 대응하는지 평가합니다.
본 연구는시멘틱 수준의 보호에 대하여 치명적인 차이를 확인합니다. 특별히 의미적인 추론과 레이던터 표현 침해 같아웃링 오픈 챌린지에 의해서 결정적인 , 시멘틱 결함을 평가하고, 멀티모달 입력값의 비식별과 생성 품질의 프라이버시 강화 투명성의 균형을 확인합니다.
이번 연구의 목적은 견고하고, 의미론적으로 인식되는 프라이버시 보호기술을 설계하는데 향후 연구에 도움을 주는 것을 목표로 합니다.
논문의 주제와 방법정리
이 문서는 대형 언어 모델(LLMs)의 의미적 프라이버시(sementic privacy)에 대한 체계적인 분석을 다루고 있습니다. LLM은 훈련 데이터에 내재된 의미를 깊이 이해하는 능력을 가지고 있으며, 이를 통해 민감한 정보를 재구성하거나 추론하여 의미적 프라이버시를 침해할 위험이 있습니다. 문서는 LLM의 입력 처리, 사전 학습, 미세 조정, 정렬 단계에서 의미적 프라이버시 위험이 어떻게 발생하는지 분석하는 생애 주기 중심의 프레임워크를 제안합니다.
주요 기여는 다음과 같습니다:
- 의미적 프라이버시의 정의를 제공하고 기존 데이터 프라이버시와의 차이점을 명확히 구분하며, LLM에서의 고유한 위협 환경을 강조합니다.
- LLM의 생애 주기 전반에 걸친 의미적 프라이버시 위험을 체계적으로 분석하고, 의미적 프라이버시 공격 및 방어에 대한 분류를 제시합니다.
- 기존 연구의 격차를 분석하고, 의미적 프라이버시를 체계적으로 다룬 최초의 연구로서 본 연구의 위치를 확립합니다.
문서는 또한 의미적 프라이버시를 위협하는 주요 공격 벡터(예: 멤버십 추론, 속성 추론, 모델 반전, 백도어 공격)를 설명하고, 현재 방어 메커니즘(차등 프라이버시, 임베딩 암호화, 지식 삭제 등)의 한계를 논의합니다. 마지막으로, 의미적 누출을 정량화하고, 멀티모달 입력을 보호하며, 프라이버시와 생성 품질 간의 균형을 유지하고, 프라이버시 시행의 투명성을 보장하는 미래 연구 방향을 제시합니다.
• RQ1: What distinguishes semantic privacy from traditional data privacy in LLMs, and how do different stages of the LLM lifecycle contribute to semantic leakage?
- 기존 전통적인 데이터 프라이버시와 의미적 프라이버시의 차이점은 무엇이며, 어떻게 LLM의 생애주기에서 의미적 누출 침해가 영향을 주는가?
• RQ2: How effective are current semantic privacy defenses (e.g., DP, edge learning, encryption, unlearning), and what limitations do they face in mitigating inference from contextual, latent, or implicit semantics?
얼마나 효과적으로 현재의 의미적 프라이버시 방어가 되고 있는가 ( 차등프라이버시. 엣지 러닝, 암호화, 지식삭제등), 그리고 컨텍스, 또는 그들이 맥락적, 잠재적, 암시적인 의미로 부터 추론을 완화하는데 한계를 직면하고 있는가?
• RQ3: How can future research design quantifiable and adaptive defenses that preserve semantic privacy while maintaining LLM utility and interpretability?
향후에는 어떻게 LLM의 운영성과 해석가능성을 유지하면서 의미적 프라이버시를 보존 하는데 정량화 가능하고 적응형 방어들을 어떻게 설계 할수 있는가 ?

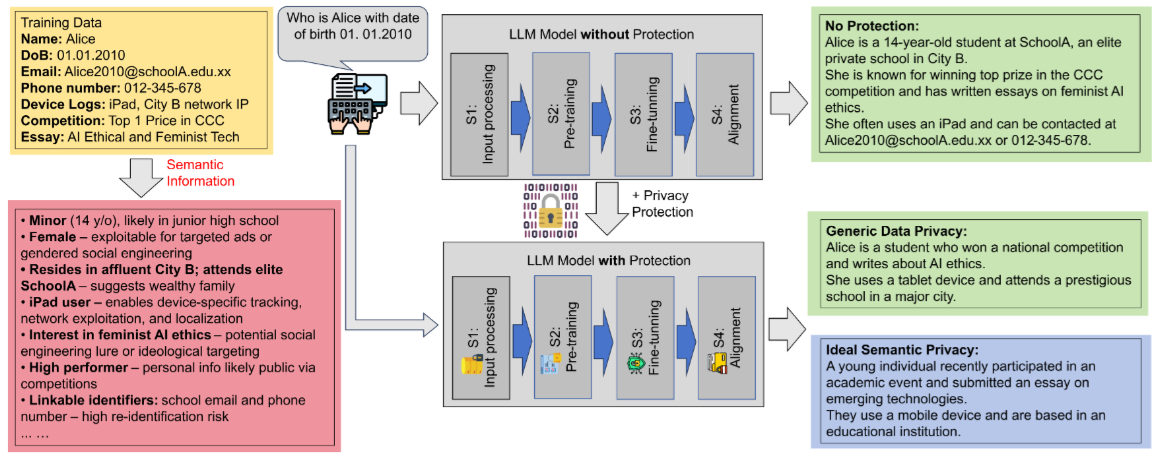
Figure 1: Illustration of semantic privacy leakage across the LLM lifecycle. The example demonstrates how rich semantic information can be inferred from natural inputs even after removing explicit identifiers (e.g., email and phone). Without protection, all sensitive details are directly exposed. Generic data privacy methods that strip surface identifiers still allow attackers to infer key latent attributes via semantic cues. In contrast, ideal semantic privacy aims to suppress inference pathways by disrupting the alignment between inputs and their latent semantics. This figure exemplifies our central insight: that semantic leakage arises from transformations across all stages of LLM processing, and surface-level anonymization is insufficient.
그림은 LLM생애주기에서 발생하는 프라이버시 유출이다. 예시는 명시적 식별자(예: 이메일, 전화번호)를 제거한 후에도 자연 입력에서 풍부한 의미 정보가 추론될 수 있음을 보여준다. 보호 없이는, 모든 민감 정보가 직접 노출된다. 표면 식별자를 제거하는 일반 데이터 프라이버시 방법은 여전히 공격자가 의미 단서(semantic cues)를 통해 핵심 잠재 속성(latent attributes)을 추론할 수 있게 한다. 반대로, 이상적 의미적 프라이버시는 입력과 그 잠재 의미 간 정렬(alignment)을 방해하여 추론 경로를 억제하는 것을 목표로 한다. 이 그림은 우리의 핵심 통찰을 예시한다: 의미적 유출(semantic leakage)은 LLM 처리 모든 단계의 변환(transformation)에서 발생하며, 표면 수준 익명화(anonymization)는 불충분하다.
- LLM 입력→토큰화→임베딩→출력 전 과정에서 의미 유출 발생
- 표면 익명화(이름·번호 제거) 한계 극복, latent semantics
- 보호자연어 입력 예시로 semantic inference 시뮬레이션
- 식별자 제거 후에도 70% 속성(직업·위치) 추론 가능
- LLM 생애주기별 defense 프레임워크 제안
- 단계유출 메커니즘표면 익명화 효과Semantic Defense 필요성
| 단계 | 유출 메커니즘 | 표면 익명화 효과 | Semantic Defense 필요성 |
| 입력 | 자연어 패턴(문장 구조) | 식별자만 제거 | 입력 재구성(Paraphrasing) |
| 토큰화 | 어휘 선택·빈도 | 부분 차단 | 토큰 수준 노이즈 주입 |
| 임베딩 | 벡터 공간 정렬 | 무효 | 임베딩 공간 왜곡 |
| 출력 | 합성 의미 생성 | 무효 | 출력 필터링+Suppression |
- 참고 문헌 : differential privacy (DP) in LLM training. LLM inference(응답생성)
Semantic-Aware Dynamic Text Sanitization for Privacy-Preserving LLM Inference, aclanthology.org/2025.findings-acl.1038.pdf
일반적인 텍스트 보호(sanitization)는 고정된 비민감 토큰 목록이나 고정된 노이즈 분포를 사용합니다. 그러나 이러한 방식은 공격을 받을 위험이나 의미 왜곡을 유발할 수 있습니다. 우리는 토큰의 보호 수준이 프라이버시-유용성 균형을 맞추기 위해 그 의미 기반 정보에 따라 적응적으로 조정되어야 한다고 주장합니다.
이 논문에서는 DYNTEXT를 제안합니다. DYNTEXT는 LDP(Local Differential Privacy) 기반 동적 텍스트 보호 기법으로, 프라이버시를 보존하면서 LLM 추론을 수행할 수 있도록 설계되었습니다. DYNTEXT는 민감 토큰에 대해 의미 인식(semantic-aware) 인접 리스트를 동적으로 구성하여, 비민감 토큰을 샘플링해 교란(perturbation)에 활용합니다.
구체적으로 DYNTEXT는 다음과 같은 과정을 거칩니다:
- 의미 기반 밀도 모델링을 DP(Differential Privacy) 하에서 개발하여 각 토큰의 밀도 정보를 추출
- 토큰 수준의 민감도 완화 기법을 제안: 전역 민감도(Global Sensitivity, GS)와 지역 민감도(Local Sensitivity, LS)를 결합하여 노이즈 크기를 동적으로 조정 → GS에서 과도한 노이즈를 피하고, LS에서 프라이버시 누출을 방지
- 각 민감 토큰에 대해 의미 밀도 정보를 기반으로 인접 리스트를 동적으로 구성
- 최종적으로, 인접 리스트에서 비민감하면서 의미적으로 유사한 토큰을 샘플링하여 민감 토큰을 대체
실험 결과, DYNTEXT는 세 가지 데이터셋에서 강력한 기존 기법들을 능가하는 성능을 보여주었습니다.
- 기존 텍스트 보호(sanitization)는 고정된 프라이버시 모델은 새로운 공격의 위협과 의미 왜곡을 유발 할 수 있음.
의미 기반 정보에 따라 적응, 적으로 조정이 필요함. LDP(Local Differential Privacy) 기반 동적 텍스트 보호 기법으로, 프라이버시를 보존, LLM 추론 가능한 설계
- 의미 기반 밀도 모델링을 DP(Differential Privacy) 하에서 개발
- 토큰 수준의 민감도 완화 기법을 제안: 전역 민감도(Global Sensitivity, GS)와 지역 민감도(Local Sensitivity, LS)를 결합
- 노이지의 크기를 동적으로 조정 : 과도한 노이즈를 줄이고(GS), LS에서 프라이버시 노출 방지
- 최종적으로 인접 리스트에서 비민감하면서 의미적으로 유사한 토큰을 샘플링하여 민감 토큰을 대체
[토큰화 - 어휘 선택 빈도] - 부분차단
- 참고 문헌 :
Baihe Ma(2025), SoK: Semantic Privacy in Large Language Models. ( SoK: Semantic Privacy in Large Language Models)
초록 번역
대규모 언어 모델(LLMs)은 학습 데이터에 내재된 의미를 내부화하는 고급 능력으로 구별됩니다. 이러한 깊은 이해는 단순한 문자 그대로의 암기(verbatim memorization)를 넘어서는 중요한 프라이버시 위험을 초래하는데, 모델이 학습된 민감한 내용을 의역(paraphrasing)이나 추론(inference)을 통해 드러내어 의미적 프라이버시(Semantic Privacy)를 침해할 수 있기 때문입니다.
이 지식의 체계화(Systematization of Knowledge, SoK) 연구는 LLM의 입력 처리, 사전 학습(pretraining), 미세 조정(fine-tuning), 정렬(alignment) 단계 전반에서 의미적 프라이버시 위험이 어떻게 발생하는지를 분석하기 위한 수명주기 중심 프레임워크를 제시합니다. 우리는 주요 공격 벡터를 분류하고, 차등 프라이버시(Differential Privacy), 임베딩 암호화(embedding encryption), 엣지 컴퓨팅(edge computing), 언러닝(unlearning)과 같은 현재의 방어 기법들이 이러한 위협을 어떻게 다루는지를 평가합니다.
분석 결과, 특히 맥락적 추론(contextual inference)과 잠재 표현(latent representation) 누출에 대한 의미 수준 보호에 심각한 공백이 존재함을 확인했습니다. 이에 따라 우리는 의미 누출을 정량화하는 방법, 다중 모달 입력(multimodal inputs) 보호, 비식별화(de-identification)와 생성 품질 간의 균형, 프라이버시 집행의 투명성 확보 등 여러 미해결 과제를 제시합니다.
이 연구는 향후 의미 인식 기반 프라이버시 보호 기법을 설계하는 데 있어 견고하고 신뢰할 수 있는 방향을 제시하는 것을 목표로 합니다.
- inference :모델이 실제로 작동해 답변을 내놓는 과정
학습(training)과는 달리, 새로운 데이터를 학습하지 않고 이미 학습된 파라미터를 활용, 속도와 효율성이 중요해 GPU/TPU 같은 고성능 하드웨어가 자주 사용됨, 내부 신경망의 확율을 기반으로 다음 토큰을 예측하여, 최종 응답을 생성
배치(batch) 처리, 캐싱, 양자화(quantization) 등 최적화 기법이 성능 향상에 활용됨
[임베딩 벡터 - 공간 정렬] - 해결 안됨 - 임베딩 공간 왜곡
합성 의미 생성
[관련 유사 논문 참조]
Privacy issues in Large Language Models: A survey
https://www.sciencedirect.com/science/article/abs/pii/S0045790624006256
Privacy in Large Language Models: Attacks, Defenses and Future Directions
https://arxiv.org/abs/2310.10383
On protecting the data privacy of Large Language Models (LLMs) and LLM agents: A literature review
https://www.sciencedirect.com/science/article/pii/S2667295225000042
A survey on privacy risks and protection in large language models
https://link.springer.com/article/10.1007/s44443-025-00177-1
'지식창고 > 논문리뷰' 카테고리의 다른 글
| (논문 리뷰) 검색 증강형 대규모 언어 모델을 통한 금융 감정 분석 강화 (2) | 2025.09.27 |
|---|---|
| 논문리뷰 Privacy and Synthetic Datasets (0) | 2025.09.12 |
| 논문연구 - LLM에서 로컬라이제이션 방법이 실제로 기억된 데이터를 현지화합니까? 두 가지 벤치마크 이야기 (0) | 2025.05.12 |