Cultural Bias and Cultural Alignment of Large Language Models (Tao et al., 2024) — 논문 심층 분석
ㅁ Cultural Bias and Cultural Alignment of Large Language Models
- APA: Tao, Y., Viberg, O., Baker, R. S., & Kizilcec, R. F. (2024). Cultural bias and cultural alignment of large language models. PNAS Nexus, 3(9), pgae346.
- 연관성: GPT 계열 5개 모델을 대상으로 각국 대표 설문 데이터와 비교해 문화적 편향을 평가했다
연구 배경
문화는 개인의 사고, 행동, 의사소통 방식을 근본적으로 형성하며, 물체 인식(분석적 vs. 전체적), 행동 귀인(개인 특성 vs. 상황), 모순 해결 방식(타협 vs. 논리) 등 인지 과정 전반에 걸쳐 영향을 미친다 [1]. 그런데 GPT를 위시한 LLM들은 인터넷 상의 특정 지역·언어·문화권 데이터에 편중된 학습 코퍼스를 사용하기 때문에, 이를 전 세계가 사용할 경우 문화적 편향(Cultural Bias)이 사람들의 진정성 있는 표현을 왜곡하고 특정 문화의 지배력을 강화할 수 있다는 우려가 커졌다 [1]. 기존의 문화 편향 완화 연구는 (1) 다른 언어로 프롬프트, (2) 문화 관련 데이터 파인튜닝, 두 가지였으나 전자는 14개국 비교에서 효과가 없었고 후자는 전문적 자원이 필요해 접근성이 낮았다 [1].
연구 목적
본 연구는 세 가지 목적을 가진다 [1].
- 107개국을 대상으로 GPT 5개 버전의 문화적 편향을 정량적·비교적으로 측정(Disaggregated Evaluation)
- GPT 모델 세대별 문화 가치 표현의 시계열 변화 추적(2020~2024년, 4년 종단)
- 자원 없이도 누구나 적용 가능한 문화적 프롬프팅(Cultural Prompting)의 편향 완화 효과 검증
평가 기준 선정 근거와 이론
World Values Survey (WVS) 및 Integrated Values Surveys (IVS) 선택 근거
WVS는 수십 년간 축적된 사회과학의 최대 비상업적 문화 가치 측정 도구로, 120개 참여국·전 세계 인구의 90% 이상을 대표하며 광범위한 실증 연구에서 검증된 신뢰도를 가진다 [1]. 유럽 가치 연구(EVS)와 결합한 IVS 데이터셋은 총 107개국 393,536개 개인 수준 응답을 포함하며, 문화 맵 재현에 필요한 충분한 대표성을 확보한다 [1].
Inglehart–Welzel 세계문화지도(World Cultural Map) 선택 근거
Inglehart & Welzel(2005)의 문화 지도는 수십 년간 대규모 비교문화 연구의 표준 시각화 도구로, 두 개의 직교 차원으로 모든 국가의 문화 가치를 2D 공간에 배치한다 [1]. 이 이론적 선택의 근거는 다음과 같다.
| 문화 가치의 이론적 배경 | ||
|---|---|---|
| 차원 | 내용 | 이론적배경 |
| 생존 vs. 자기표현 가치 (Survival vs. Self-Expression) | 경제·물리적 안전 강조 ↔ 환경보호·다양성 관용·성평등·웰빙 강조 | Inglehart의 탈물질주의 이론(Post-Materialism Theory, 1977) |
| 전통 vs. 세속-합리적 가치 (Traditional vs. Secular-Rational) | 종교·가족 권위·민족주의 강조 ↔ 세속성·이혼·낙태 수용 | 베버(Weber)의 근대화 이론 + 잉글하트의 세계화 이론 |
이 2차원 구조는 PCA(주성분 분석)를 통해 10개 IVS 문항에서 추출되며, 분산의 39%를 설명한다 [1]. Bolukbasi et al.(2016)이 언어 모델에서 "man → 프로그래머, woman → 주부"의 의미 근접성으로 성별 편향을 증명한 방법론과 동일한 논리 구조를 문화 편향에 적용한 것이다 [1].
문화적 편향 10개 측정 문항 선정 근거
IVS 전체 문항 은행에서 문화 지도 생성에 사용되는 표준 10개 문항을 그대로 사용했으며, 이는 Inglehart와 Welzel이 전 세계 문화 가치의 핵심 차원을 포착하기 위해 선별한 것이다 [1].
| 문항 ID | 내용 | 측정 차원 |
|---|---|---|
| A008 | 행복감(Happiness) | 자기표현 |
| A165 | 타인 신뢰(Trust) | 자기표현 |
| E018 | 권위 존중(Authority) | 전통-세속 |
| E025 | 청원 서명 경험(Civic Participation) | 자기표현 |
| F063 | 신의 중요성(Importance of God) | 전통-세속 |
| F118 | 동성애 정당성(Homosexuality) | 자기표현 |
| F120 | 낙태 정당성(Abortion) | 전통-세속 |
| G006 | 민족 자긍심(National Pride) | 전통-세속 |
| Y002 | 탈물질주의 지수(Post-Materialist Index) | 자기표현 |
| Y003 | 자율성 지수(Autonomy Index) | 자기표현 |
연구 방법
평가 설계: GPT-4o/4-turbo/4/3.5-turbo/3 5개 모델에 10개 IVS 문항을 동일 조건에서 질의하고, 응답을 IVS 데이터의 평균·표준편차로 표준화한 뒤 PCA를 적용해 문화 지도 좌표로 변환했다 [1]. 프롬프트 문구 변동에 따른 민감성을 통제하기 위해 "average human being", "typical person", "world citizen" 등 10개 유의어 변형을 적용했으며, GPT-3는 모델 폐기 전 변형 0번만 적용했다 [1].
문화적 편향 측정: LLM이 응답한 좌표와 IVS 기반 해당 국가 좌표 사이의 유클리드 거리(Euclidean Distance)를 편향 지표로 사용했다 [1]. 편향 완화 전략으로는 "당신은 [국가]에서 태어나 거주 중인 평균적인 사람입니다"라는 한 문장을 추가하는 문화적 프롬프팅(Cultural Prompting)을 제안하고, Wilcoxon 부호 순위 검정으로 유의성을 검증했다 [1].
연구데이터
https://github.com/The-Responsible-AI-Initiative/LLM_Ethics_Benchmark.git
표준화된 평가 : 도덕적 기초 설문지(MFQ), 세계 가치관 조사(WVS), 도덕적 딜레마를 활용합니다.
다양한 LLM 모델 지원 : Claude, GPT-4 및 기타 모델을 일관된 방법론으로 평가합니다.
정량적 지표 : 검증된 정답 데이터를 기반으로 정렬 점수를 계산합니다.
추론 분석 : 정답뿐 아니라 도덕적 추론의 질과 일관성을 평가합니다.
연구 결과
모든 GPT 모델은 기본 응답에서 영어권 및 개신교 유럽 국가(핀란드·안도라·네덜란드·뉴질랜드 등)의 가치와 가장 가까웠으며, 요르단·리비아·가나 등 아프리카-이슬람권 국가와 가장 멀리 떨어졌다(GPT-4o 기준 요르단 거리 d=4.10) [1]. 구체적으로 5개 모델 모두 자기표현 가치(Self-Expression) 방향의 편향이 일관되게 확인됐으며, 이는 훈련 데이터의 불균등 분포, 영어 프롬프트 효과, 미국 개발팀의 가치관 내재화 중 하나 이상에서 기인하는 것으로 분석된다 [1].
문화적 프롬프팅의 효과는 최신 모델에서 더 우수했으며, GPT-4o는 평균 문화 거리를 2.42→1.57(p<0.001), GPT-4-turbo는 2.71→1.77(p<0.001)로 유의미하게 감소시켰다 [1]. 전통-세속 차원에서는 모델 간 변동이 관찰됐는데, GPT-3.5-turbo의 RLHF 도입이 세속적 가치 편향을 강화한 반면, GPT-4의 규칙 기반 보상 모델(Rule-Based Reward Model)이 이를 일부 완화했을 가능성이 제기됐다 [1].
연구 시사점
이 연구는 문화 편향을 추상적 주장이 아니라 정량적 거리로 측정해 AI 기업에게 실용적인 모니터링 도구를 제공했다는 점에서 방법론적 기여가 크다 [2]. Responsible AI Initiative(2025) 논문의 핵심 한계로 지적된 "서구 규범 중심 편향"이 실제로 얼마나 심각한지를 107개국 수준에서 실증했으며 [3], "문화적 프롬프팅"이라는 단 하나의 문장 추가로 71~81%의 국가에서 편향을 완화할 수 있다는 발견은 현장 적용 가능성을 높인다 [4].
연구 한계
- 프롬프트 언어 의존성: 분석이 영어 프롬프트로만 진행되어 다른 언어 환경에서의 편향 패턴이 검증되지 않았다 [1].
- 설문 외 행동으로의 일반화 불가: 인간의 WVS 응답은 실제 행동과 상관관계가 있지만, LLM의 설문 응답이 실제 출력 행동을 예측한다고 가정하기 어렵다 [1].
- 폐쇄형 모델의 불투명성: GPT는 폐쇄 소스 모델로 훈련 데이터 세부 사항이 미공개되어 편향의 인과 메커니즘을 규명할 수 없으며, 연구 재현 가능성도 제한된다 [1].
- 문화적 프롬프팅의 불완전성: 19~29%의 국가에서는 문화적 프롬프팅이 오히려 편향을 악화시키며, 특히 GPT가 이미 잘 정렬된 핀란드·스위스 같은 국가에서 역효과가 발생했다 [1].
- 단일 모델 제공사 분석: GPT 계열 5개 버전만 다뤄 Claude·Mistral·LLaMA 등 타 LLM으로의 일반화에 한계가 있다 [3].
발전 방향
저자들이 제시한 향후 과제는 다음과 같다 [1].
- 동일 방법론으로 오픈웨이트 모델(LLaMA, Mistral 등)의 문화 편향 평가
- 복잡한 텍스트 생성 작업과 장문 태스크로 문화적 프롬프팅 효과 확장 연구
- LLM의 AI 리터러시 교육 과정 통합: "LLM은 문화적으로 편향되어 있지만 사용자가 프롬프팅으로 이를 어느 정도 제어할 수 있다"는 원칙의 교육화
- 지속적 모니터링 파이프라인 구축: 제안된 평가 방법론을 AI 개발사와 서비스 제공자가 모델 업데이트 시마다 주기적으로 실행하도록 권고
- 비서구 문화권의 맥락 의존적 도덕 딜레마를 포함한 벤치마크 확장(Responsible AI Initiative, 2025의 한계와 직결)

연구 방법에 대한 세부 사항
논문 "Cultural Bias and Cultural Alignment of Large Language Models" (Tao et al., 2024)에서 Inglehart–Welzel 세계문화지도 이론을 LLM의 문화적 편향 분석에 실제로 어떻게 접목하고 구현했는지, 그 분석 절차와 과정의 이론적 방법론을 단계별로 정리합니다.
이 연구는 사회과학의 문화 비교 이론을 컴퓨터 과학의 자연어 처리(NLP) 방법론(특히 단어 임베딩 공간 분석)으로 변환하는 구조를 취하고 있습니다.
사회과학적 분석 도구(주성분 분석, PCA)가 최신 컴퓨터 과학 연구(Tao et al., 2024 논문)와 만났을 때 각각 어떤 역할과 특징을 갖는지에 대한 핵심을 정리합니다.
분석모형 - 주성분과 Tao et al.
- 주성분 분석(PCA)은 인간 사회과학 데이터에서 '문화의 나침반 축(2차원)'을 정립한 도구라면,
- Tao et al. (2024) 논문은 그 나침반을 들고 AI의 내면(LLM 출력)을 측정하여, "기본 상태의 AI는 서구 가치관을 가리키고 있지만, 적절한 프롬프팅을 주면 전 세계 다양한 국가의 실제 가치관 좌표로 조조정(Alignment)이 가능하다"는 것을 정량적으로 밝혀낸 연구입니다.
1. 주성분 분석 (PCA)의 역할과 특징
주성분 분석(PCA, Principal Component Analysis)은 본래 잉글하트와 원젤(Inglehart & Welzel)이 실제 인간 사회의 설문 데이터(WVS)를 분석하기 위해 사용한 통계학적 차원 축소 기법입니다.
- 수많은 변수의 단순화: WVS는 인간의 가치관을 묻는 수십, 수백 개의 문항으로 구성되어 있습니다. PCA는 이 복잡한 문항들 중 서로 연관성이 높은 문항들을 묶어, 전체 데이터의 변동성(분산)을 가장 잘 설명하는 핵심 축(주성분)을 추출합니다.
- 2차원 문화 지도 형성: 분석 결과, '전통 vs 세속-합리적' 가치와 '생존 vs 자기표현' 가치라는 2개의 직교하는 주성분(축)이 도출되었습니다. 이 두 축만으로 전체 데이터 분산의 약 39%를 설명할 수 있어, 복잡한 글로벌 문화를 2D 평면 위에 명쾌하게 시각화할 수 있게 되었습니다.
- 데이터 기반의 객관성: 연구자의 주관이 아니라, 통계적으로 데이터의 차이를 가장 극명하게 가르는 기준을 찾아낸 수학적 결과물입니다.
2. Tao et al. (2024) 논문의 차별적 특징
Tao et al. (2024)의 논문은 이 고전적인 PCA 기반의 문화 지도를 현대 Generative AI(생성형 인공지능) 평가 영역으로 확장했다는 점에서 강력한 특징을 가집니다.
Tao et al. (2024)는 논리적 뼈대는 Bolukbasi의 방식을 그대로 가져왔지만, 문화라는 복잡한 개념을 다루기 위해 다음과 같은 점을 확장했습니다.
- 1차원에서 2차원으로의 확장: Bolukbasi는 주로 '남성-여성'이라는 1차원 축 위에서 단어의 위치를 보았지만, Tao et al.은 Inglehart–Welzel 이론에 따라 X축(전통-세속)과 Y축(생존-자기표현)이라는 2개의 직교하는 축을 동시에 사용하여 2D 평면 좌표를 만들었습니다.
- 단어에서 텍스트(문장)로의 확장: Word2Vec 시절의 단일 '단어(Word)' 임베딩을 비교하던 것에서 벗어나, 문맥을 가진 LLM의 '응답 문장(Sentence/Paragraph)' 전체의 임베딩을 축에 투영했습니다.
결론적으로 "단어 공간에 '성별 축'을 세워두고 특정 단어가 어디로 쏠리는지 보았던 알고리즘"을, **"LLM 벡터 공간에 '문화 가치 축' 2개를 세워두고 AI의 답변이 어느 나라 문화 쪽으로 쏠리는지 보는 방식"**으로 그대로 치환한 것입니다. 그렇기에 방법론적 뿌리가 완전히 같다고 볼 수 있습니다.
① 다세대 LLM 모델의 종단적 분석 (Evolutionary Tracking)
과거 연구들이 특정 시점의 단일 모델 편향을 본 것과 달리, 이 논문은 OpenAI의 GPT-3부터 GPT-3.5-turbo, GPT-4, GPT-4-turbo, GPT-4o에 이르기까지 총 5개 세대 모델을 순차적으로 비교했습니다.
② 기본 설정의 'WEIRD' 편향 입증
아무런 전제 조건을 주지 않았을 때(Default 상태), GPT 계열의 모든 모델이 영어권(English-speaking) 및 개신교 유럽(Protestant European) 국가의 가치관 좌표로 강하게 쏠린다는 점을 수학적으로 증명했습니다. 즉, 기술이 발전해도 기본적으로 서구 중심적 가치관(WEIRD: Western, Educated, Industrialized, Rich, Democratic)을 내포하고 있음을 지도로 시각화했습니다.
③ 제어 전략으로서의 '문화적 프롬프팅 (Cultural Prompting)' 제안 및 검증
논문은 단순히 "편향이 있다"고 비판하는 데 그치지 않고, 이를 해결할 공학적 방법론을 제시했습니다.
- 페르소나 부여: 모델에게 "당신은 <국가명>에 사는 사람입니다"라는 문화적 정체성을 주입(Cultural Prompting)하는 실험을 진행했습니다.
LLM 문화 편향 분석의 이론적 절차 및 과정
1. 문화적 가치 축의 벡터화 (Theoretical Anchoring)
논문은 Inglehart-Welzel 이론의 두 가지 핵심 차원(전통vs세속-합리적, 생존vs자기표현)을 LLM이 이해하는 벡터 공간에 투영하기 위해 고정점(Anchor)을 정의합니다.
- 설문 문항의 벡터 변환: WVS(세계가치조사)에서 추출한 10개 핵심 문항 및 관련 키워드를 LLM에 입력하여 각 문항에 대한 임베딩 벡터를 추출합니다.
- 직교 차원 생성 (PCA 논리의 적용): 사회과학에서 주성분 분석(PCA)을 통해 두 축을 도출한 것처럼, LLM의 고차원 벡터 공간에서 두 문화적 차원(가치 축)을 대변하는 수학적 방향 벡터($\vec{v}{\text{trad-sec}}$, $\vec{v}{\text{surv-expr}}$)를 생성합니다.
2. Bolukbasi 방식의 고정관념/편향 측정 논리 적용
Bolukbasi et al. (2016)이 단어 임베딩 공간 내에서 성별 편향(Gender Bias)을 측정하기 위해 사용한 코사인 유사도(Cosine Similarity) 및 프로젝션(Projection) 기법을 문화 차원에 그대로 이식합니다.
- 기존 연구 (성별 편향):
$$\text{Projection}(\vec{v}{\text{doctor}}, \vec{v}{\text{man}} - \vec{v}_{\text{woman}})$$
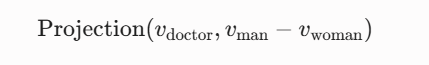
특정 직업 단어가 '남성-여성'을 잇는 직선상에서 어디에 위치하는지 측정.
- 본 연구 (문화 편향): 특정 국가, 언어, 혹은 특정 사회적 개념을 나타내는 LLM의 텍스트 생성 결과물(또는 임베딩 벡터)을 앞서 구한 '문화 가치 축'에 사영(Projection) 시킵니다.
3. 세부 분석 절차 (Step-by-Step Pipeline)
[Step 1: 문화 프롬프트 입력] ➔ [Step 2: LLM 응답 임베딩 추출] ➔ [Step 3: 2차원 문화 공간 사영] ➔ [Step 4: 실제 WVS 데이터와 비교]
Step 1: 다국어/다문화 프롬프트 설계 (Prompting)
LLM에게 문화적 가치관을 유도하는 질문(예: 낙태, 성평등, 종교, 경제적 안전 등에 대한 태도를 묻는 WVS 문항 기반 프롬프트)을 다양한 언어와 컨텍스트로 입력합니다.
Step 2: 응답 텍스트의 벡터 표현 추출 (Embedding Extraction)
대상 LLM(예: GPT, Llama 등)이 출력한 답변들의 hidden state나 출력 토큰의 임베딩 벡터를 수집합니다. 이 벡터는 해당 모델이 그 질문에 대해 가지는 '문화적 태도의 위치'를 의미합니다.
Step 3: 2D 문화 지도 상의 좌표 계산 (Mapping via Projection)
수집된 응답 벡터 $\vec{x}$와 Inglehart-Welzel의 두 축 벡터 간의 코사인 유사도를 계산하여 2차원 좌표 $(X, Y)$를 도출합니다.
- X 좌표 (전통 vs 세속-합리): $\cos(\vec{x}, \vec{v}_{\text{trad-sec}})$
- Y 좌표 (생존 vs 자기표현): $\cos(\vec{x}, \vec{v}_{\text{surv-expr}})$
Step 4: 문화적 정렬(Alignment) 및 편향(Bias) 평가
이렇게 도출된 LLM의 2D 좌표를 실제 WVS(세계가치조사)의 국가별 통계 데이터와 비교합니다.
- 문화적 편향(Cultural Bias) 확인: 특정 언어로 질문했을 때, 해당 언어권의 실제 인간 데이터(WVS) 위치가 아닌, 미국이나 서구권(WEIRD: Western, Educated, Industrialized, Rich, Democratic) 국가의 가치관 좌표 쪽으로 쏠리는지(Skewed) 확인합니다.
- 문화적 정렬(Cultural Alignment) 측정: LLM이 다양한 국가의 문화적 맥락을 얼마나 정확하게 모사하거나 대변하고 있는지 그 거리(Euclidean Distance 등)를 통해 정량화합니다.
🛠️ 방법론적 요약
이 논문의 핵심 방법론적 기여는 사회과학의 오랜 표준 도구(Inglehart–Welzel Map)를 NLP의 표상 공간 분석 기법(Embedding Projection)과 결합한 것입니다. 이를 통해 추상적이고 모호할 수 있는 LLM의 '문화적 편향'이라는 개념을 수학적 공간 상의 좌표와 거리로 시각화 및 정량화해 냈습니다.
'지식창고 > 논문리뷰' 카테고리의 다른 글
| LLM 도덕 추론 벤치마크 Aligning AI With Shared Human Values (Hendrycks et al., 2021) (0) | 2026.05.29 |
|---|---|
| 논문 조사: LLM 도덕적 추론 & AI 윤리 평가 (0) | 2026.05.29 |
| 논문연구 - SoK-Semantic-Privacy-in-Large-Language-Models-2506 (0) | 2026.02.24 |
| [논문 리뷰] SoK: Semantic Privacy in Large Language Models (0) | 2025.12.06 |
| (논문 리뷰) 검색 증강형 대규모 언어 모델을 통한 금융 감정 분석 강화 (2) | 2025.09.27 |